Inference
Inference is the process of using a machine learning model to create vector embeddings from text, images, or other data types. While you can create embeddings on the client side, you can also use Qdrant’s Inference API to generate them while storing or querying data.
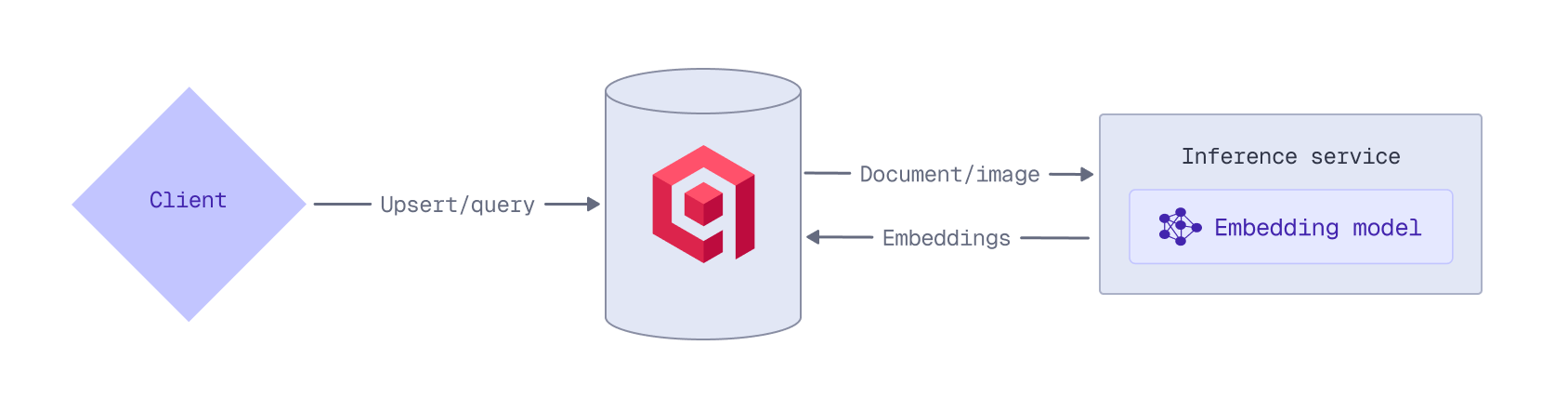
There are several advantages to generating embeddings with Qdrant:
- No need for external pipelines or separate model servers.
- Use a single, unified API instead of different APIs for each model provider.
- No external network calls, minimizing delays or data transfer overhead.
Where and how you generate embeddings depends on the model you want to use and whether you prefer to manage your own embedding infrastructure:
- Client-side inference: Manage your own inference pipeline locally, for example, using Qdrant’s Python FastEmbed library. This provides full control over the model and its configuration without external network calls and is ideal when you prefer to manage the embedding infrastructure yourself.
- Qdrant Cluster (BM25): Generate sparse embeddings using the BM25 model directly within the Qdrant cluster. This keeps the embedding logic close to the data, eliminating the need for a separate inference service for keyword-based retrieval.
- Qdrant Cloud Inference: Managed deployments on Qdrant Cloud have access to Cloud Inference. Qdrant Cloud hosts a range of embedding models, some for free, allowing you to generate embeddings without managing the infrastructure.
- Externally Hosted Models (Qdrant Cloud): Access embedding models hosted by third-party embedding model providers (OpenAI, Cohere, Jina AI, and OpenRouter). Use a wide range of state-of-the-art models through a single, unified Qdrant API, without the need to manage a separate embedding pipeline.